RLHF is only as good as the humans giving the feedback.
At G2i, our RLHF pipelines capture the judgment of engineers with an average of 7+ years of building and maintaining production systems. The hardest AI training problems increasingly require senior and staff-level software engineering expertise.
Schedule a call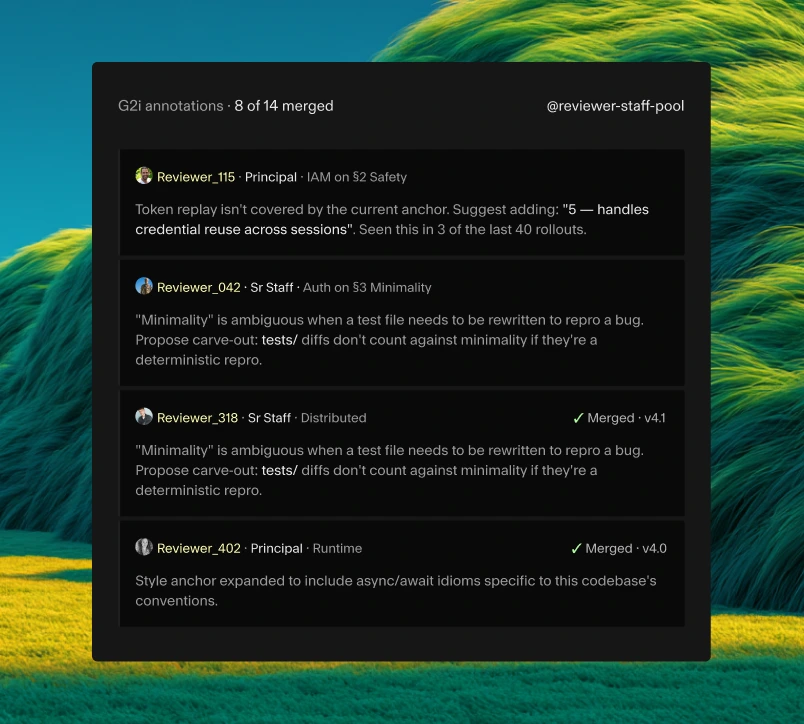
Reward signal grounded in expertise.
Generalist annotators can't tell good code from working code. Our reviewers can because they've shipped it.
Domain experts
Engineers from production, not generic crowd.
Calibrated panels
Reviewers stay aligned through checks and rotation.
Adversarial coverage
Red-team prompts and edge cases by default.
Auditable trace
Every label carries who, why, and the confidence score.
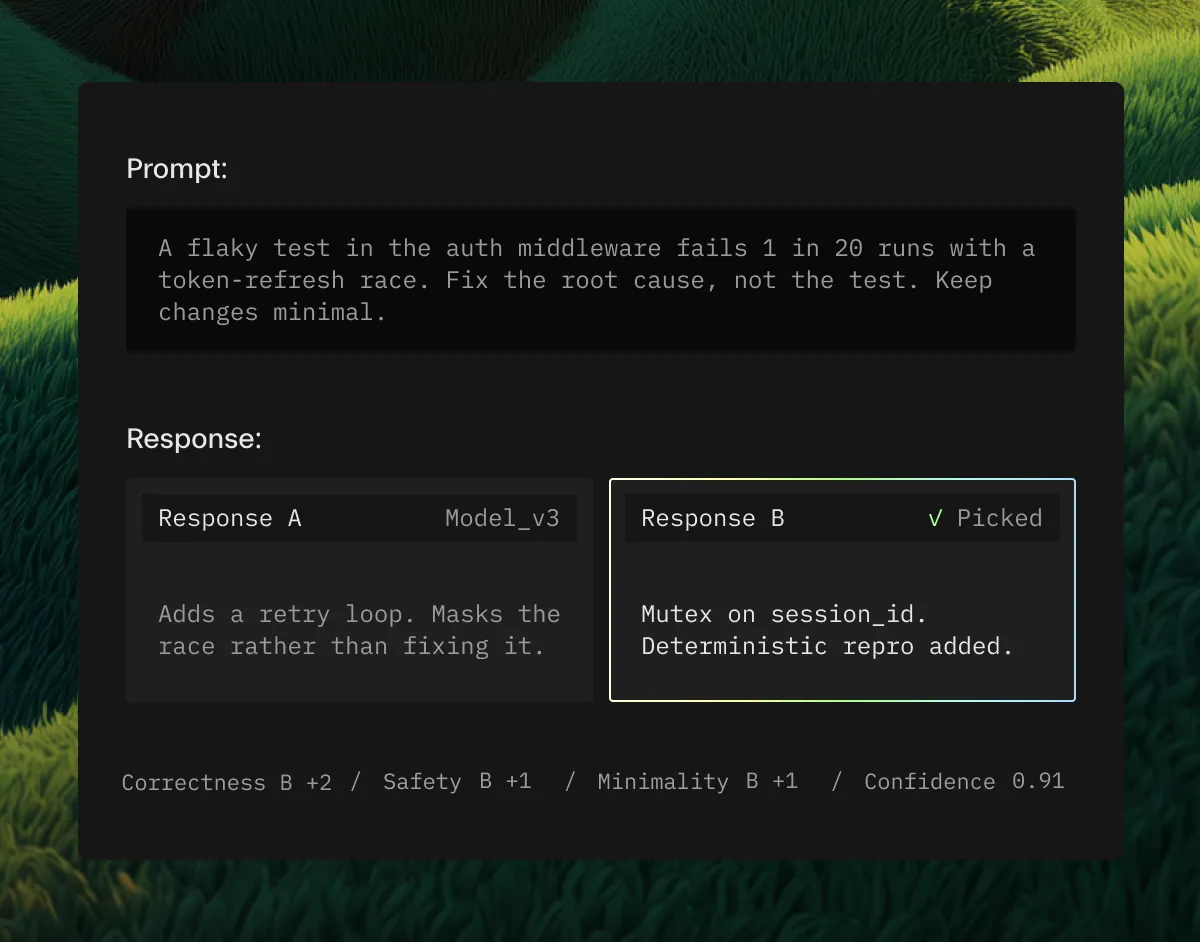
Preferences with context
Reviewers see the prompt, the rubric, and the failure modes then make a calibrated comparison. Every choice is captured with rationale, confidence, and downstream replayability.
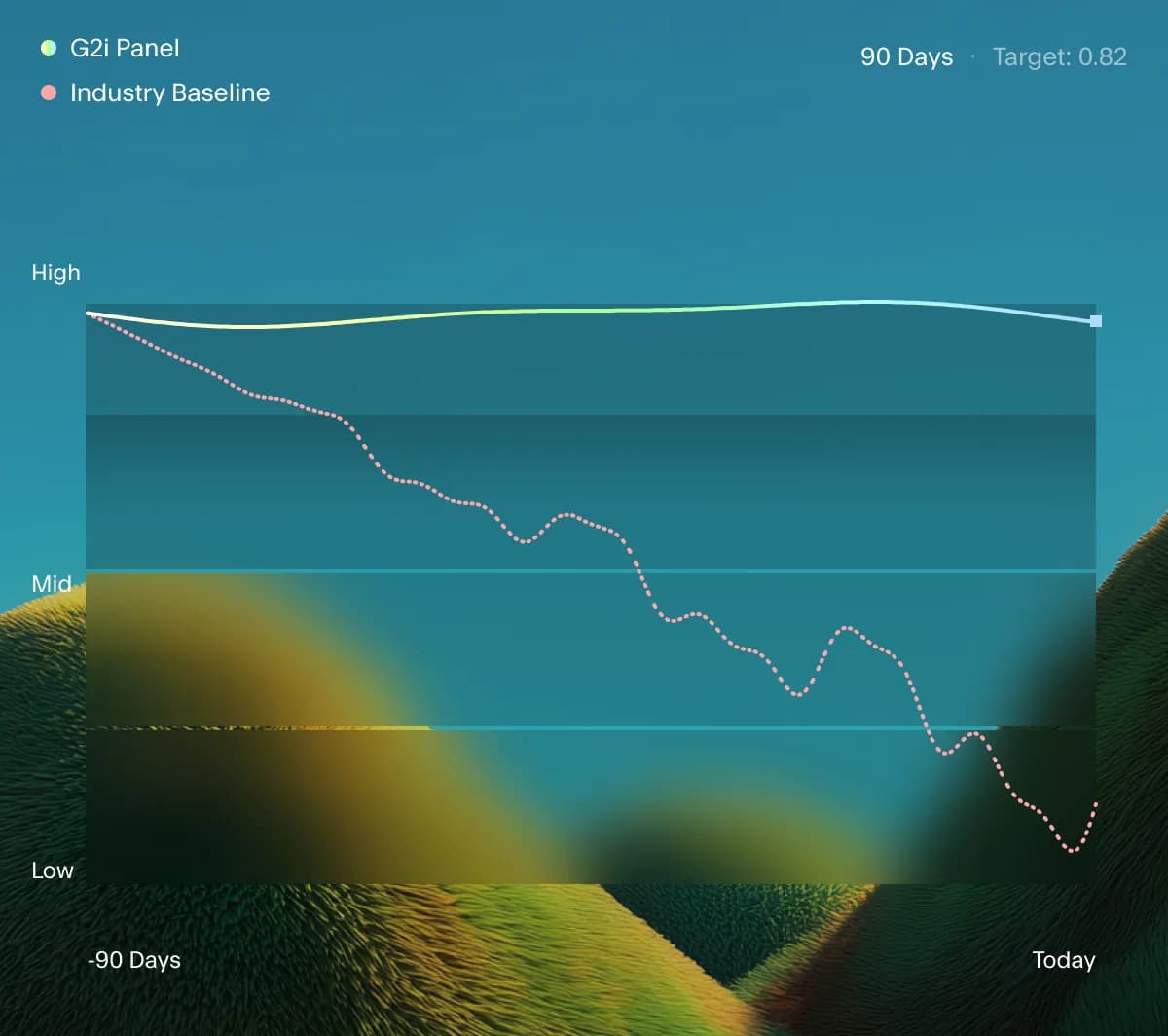
Agreement that holds at scale
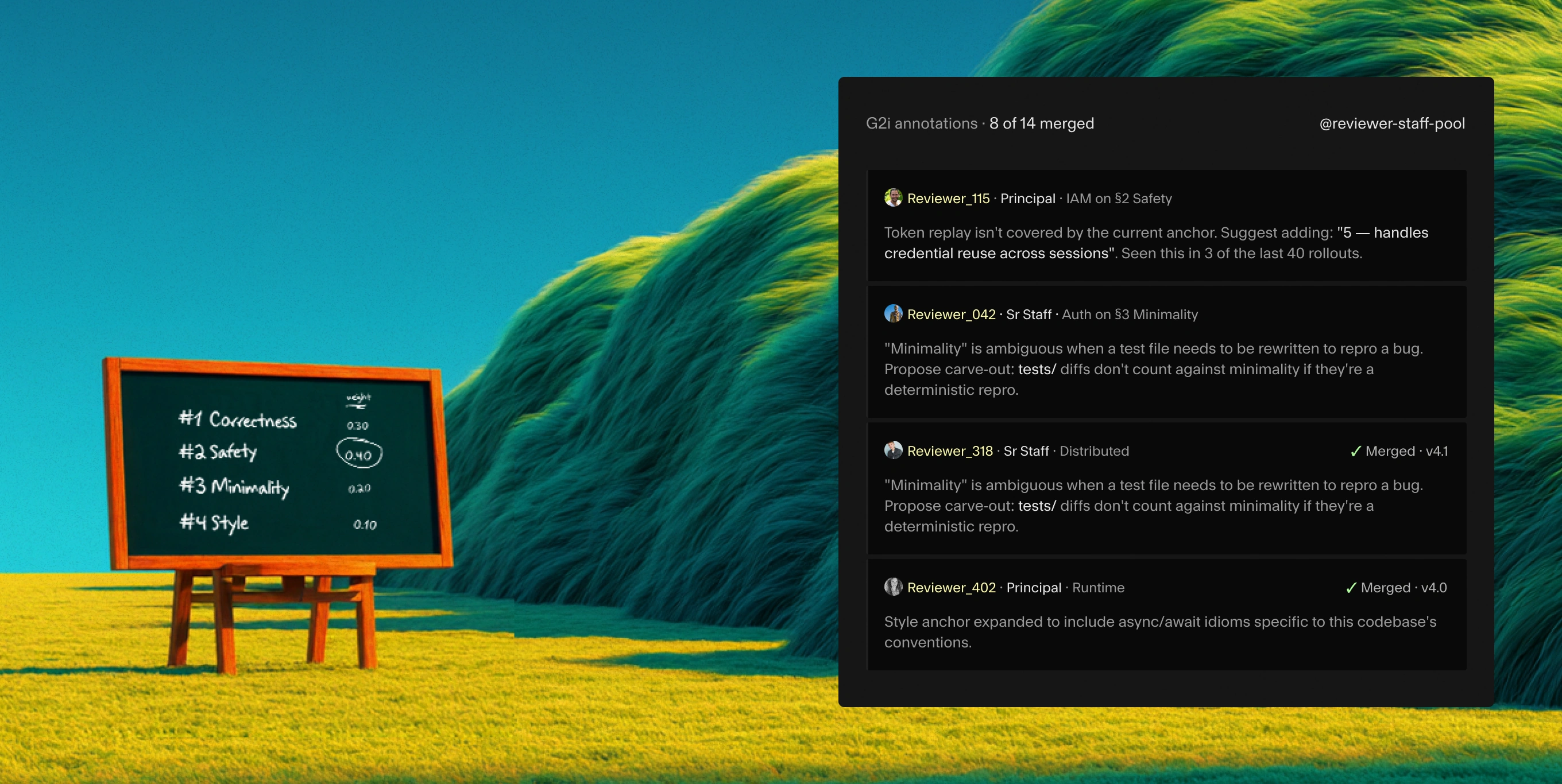
Large eval programs fall apart when reviewers drift. We keep panels calibrated with shared rubrics, reviewer rotation, golden examples, and continuous agreement checks across every batch.
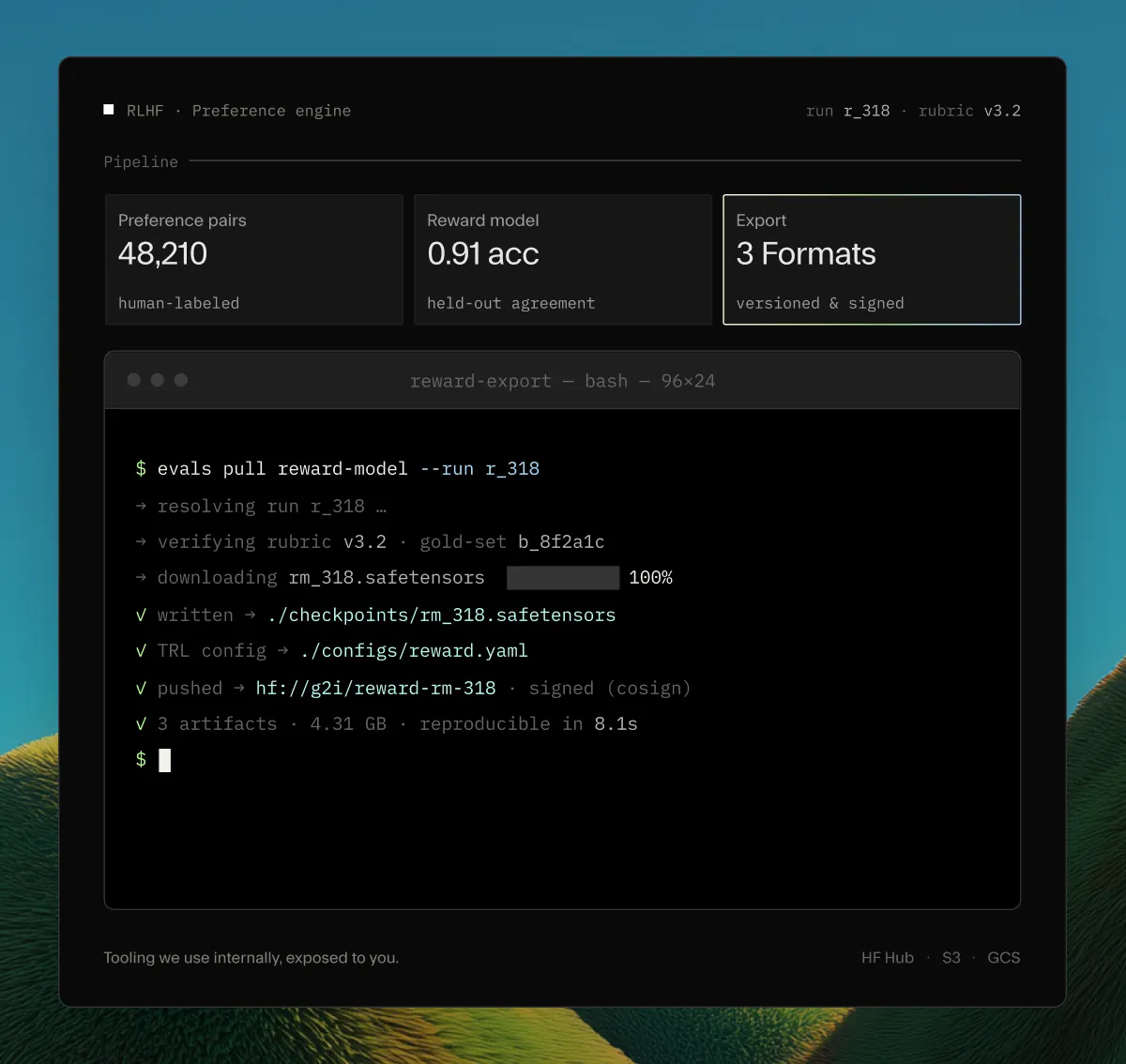
Built on our preference engine
Tooling we use internally, exposed to you. Rubric versioning, panel routing, gold set seeding, and a reward model export pipeline that drops into your training stack.
- Versioned rubrics with diff and rollback
- Automatic gold set injection for calibration
- Reward model exports

Strengthen your reward signal
Start with expert human feedback